#
Index old
딥러닝 모델이 발전하면서 수십억, 수백억 개의 파라미터를 포함하는 복잡한 구조가 되었고, 이에 따라 대규모 컴퓨팅 자원이 AI 인프라의 중요한 부분이 되었습니다. 대규모 컴퓨팅 자원을 사용하여 모델을 개발하려면 모델의 병렬 처리와 클러스터 환경의 수동 설정과 같이 학습 프로세스를 최적화하는 과정이 필수적입니다. 특히, GPU 및 노드 관리를 통한 학습 최적화는 개발자들에게 많은 시간과 노력을 요구합니다. MoAI Platform은 이러한 문제를 해결하기 위해 다음과 같은 기능을 제공하여 대규모 AI 시대에 효율적인 인프라를 지원합니다.
다양한 가속기, 다중 GPU 지원 GPU 가상화 동적 GPU 할당
#
1. 다양한 AI 가속기 지원

MoAI Platform은 다양한 AI 가속기를 지원하기 때문에 가속기 종류와 상관없이 다양한 모델 학습과 추론 작업을 실행할 수 있습니다.
사용자는 AMD, Intel 및 NVIDIA 외의 다른 AI 가속기와 함께 사용할 수 있으며, 이를 위해 기존에 활용하던 Python으로 작성된 학습 및 추론 코드를 수정할 필요가 없습니다.
#
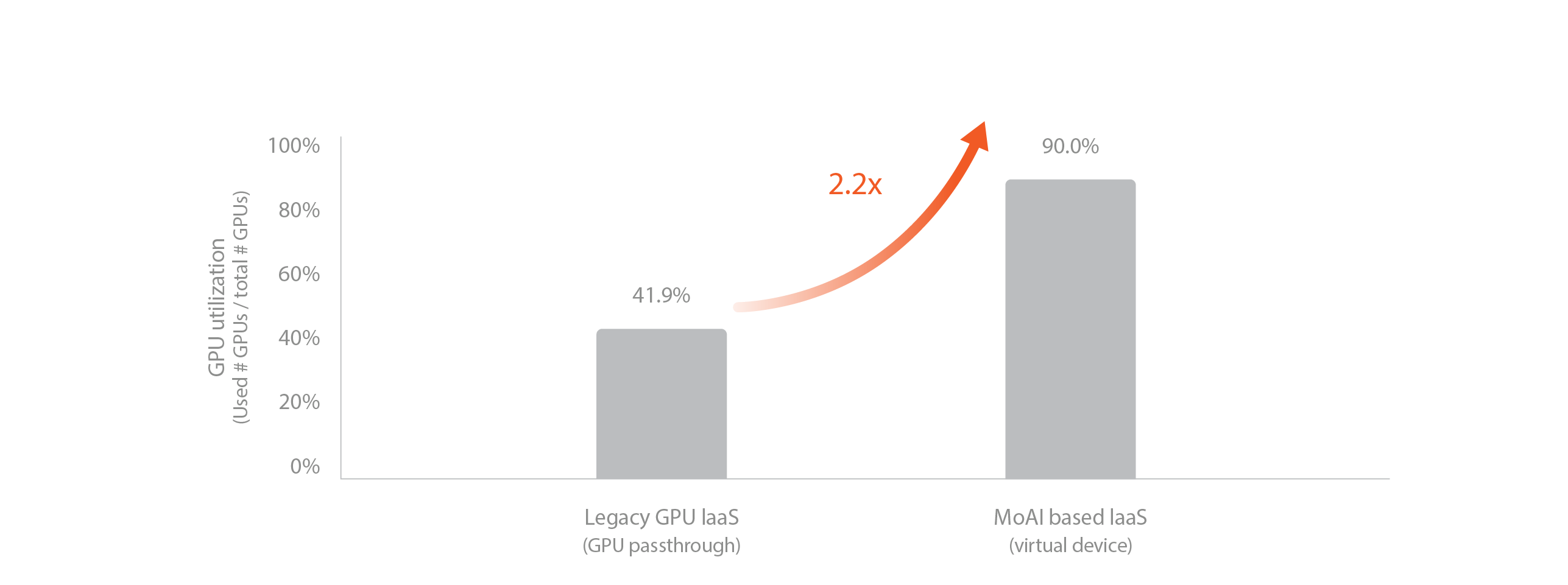
2. GPU 가상화

MoAI Platform의 가상화 기능은 수천 개의 GPU를 하나의 GPU처럼 사용할 수 있게 합니다(Single Virtual Device). 이를 통해 멀티 GPU, 멀티 노드 병렬화 작업과 같은 최적화 프로세스가 필요없이 1개의 GPU를 가정하고 Python 코드를 구성할 수 있기 때문에 AI 엔지니어가 쉽고 빠르게 딥러닝 학습 및 추론을 실행할 수 있습니다.
- 필요에 따라 GPU 자원을 확장하거나 축소할 수 있어 서비스의 확장성을 높일 수 있습니다. MoAI Platform에서는 간단한 명령어 한 줄로 1개의 Single Virtual Device 로 가상화될 GPU 자원을 손쉽게 확장하고 축소할 수 있습니다.
#
3. 동적 GPU 할당
Public Cloud에서는 VM 인스턴스 생성 시 과금이 시작되며, GPU를 변경하려면 인스턴스를 다시 생성해야 합니다. 또한 선택한 가상 머신이 한 번 확정되면 학습에 따라 유연하게 변경하기 어려운 경우도 많습니다.
MoAI Platform은 실제로 연산중일 때만 AI 가속기 사양에 따라 분 단위로 요금이 부과할 수 있는 설계이므로, 유저의 GPU 실사용시에만 과금하는 완전한 종량제 방식이 가능합니다. 이용자의 사용 패턴에 맞추어 기존 클라우드 서비스의 GPU를 특정 가상머신(VM)에 종속시키는 Passthrough 방식 대비 대규모의 비용 절감이 가능합니다.